정규표현식(RegExp, Regular Expression)
- 문자 검색(Search)
- 문자 대체(Replace)
- 문자 추출(Extract)
문자 검색, 문자 대체, 문자 추출을 하는 패턴이다.
생성 방법
// 생성자
// new RegExp('표현', '옵션')
// new RegExp('[a-z]', 'gi')
// 리터럴
// /표현/옵션
// /[a-z]/gi
const str = `
010-1234-5678
thesecon@gmail.com
Hello world!
https://www.omdbapi.com/?apikey=7035c60c&s=frozen
The quick brown fox jumps over the lazy dog.
hello@naver.com
http://localhost:1234
동해물과 백두산이 마르고 닳도록
abbcceddddeeeee
`;

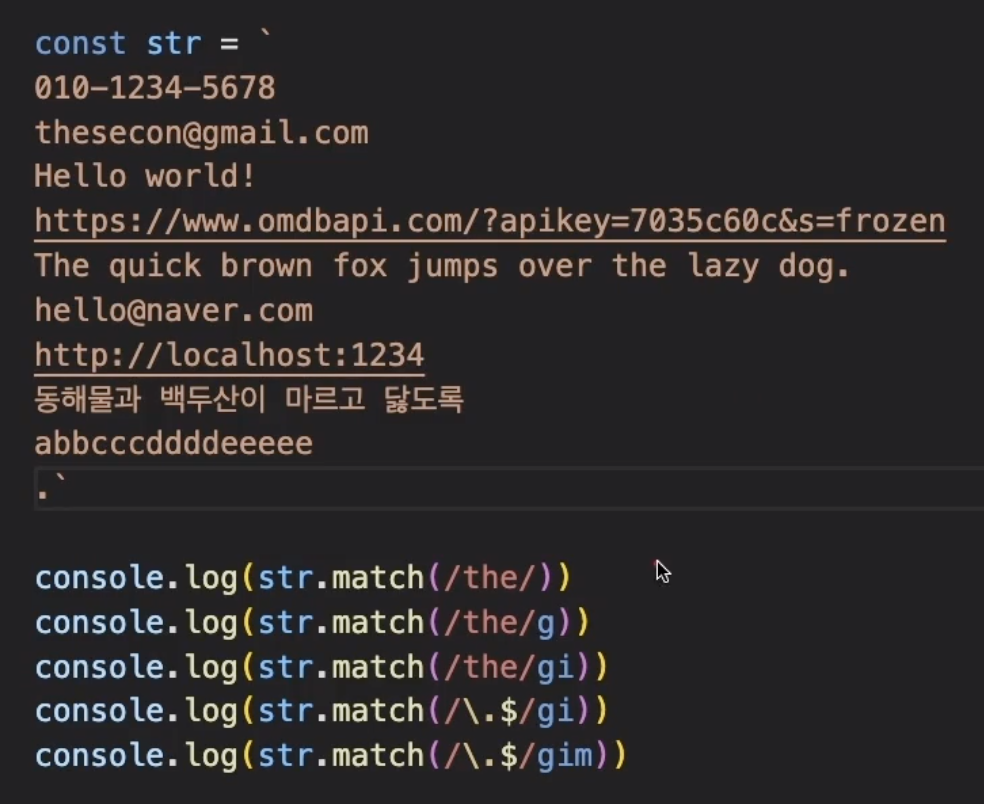
match 메서드를 사용한 결과값을 콘솔로 출력해보면 다음과 같다. 검색된 결과값은 유사 배열이다.
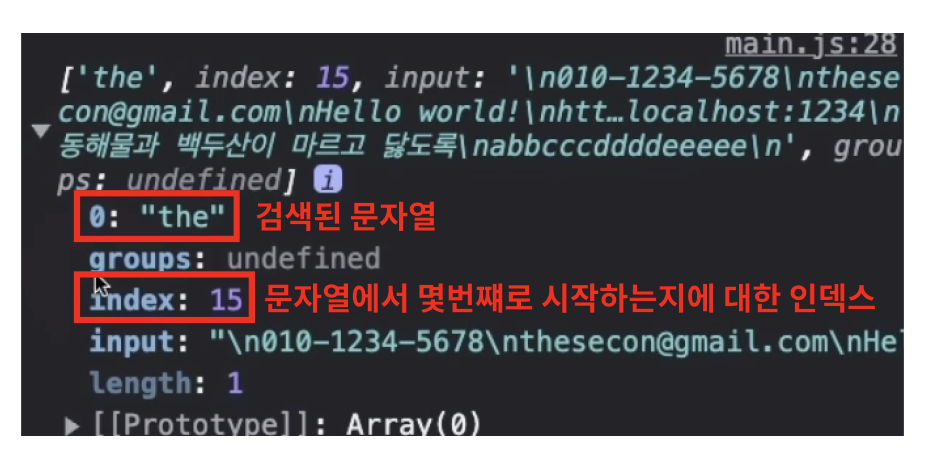
그런데 문자열을 살펴보면 the 라는 문자열은 몇개 더 있다.
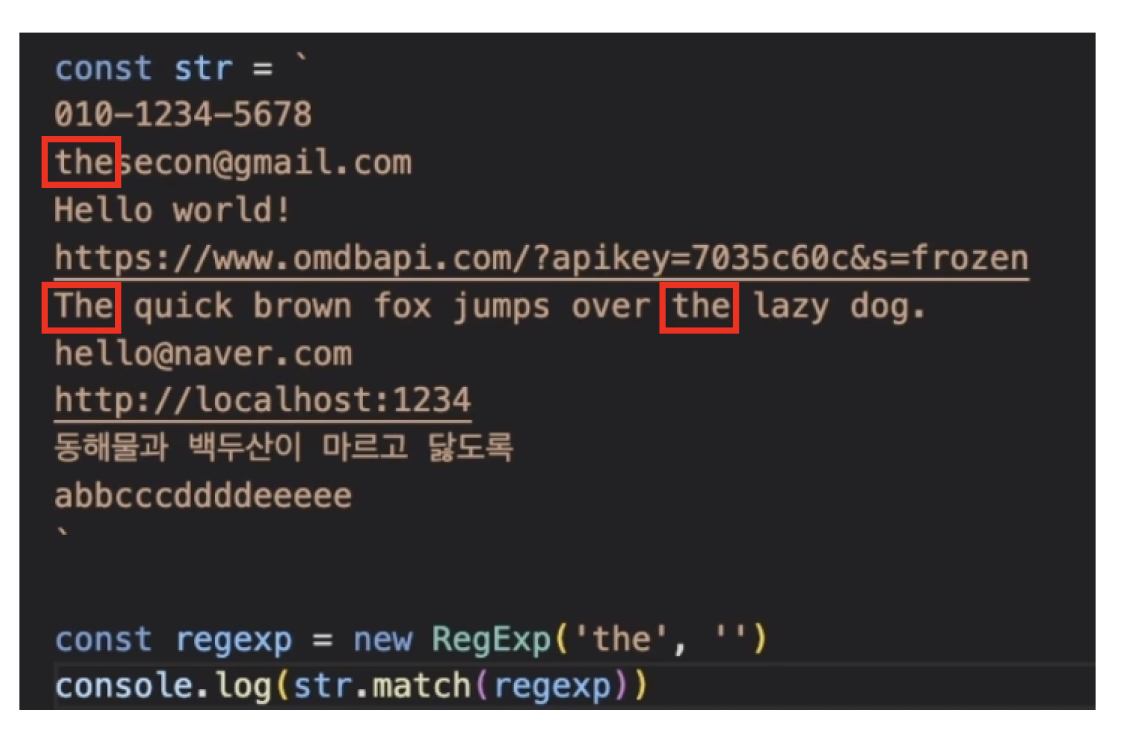
모두 찾기 위해서는 g(global) 키워드를 붙여주면된다.
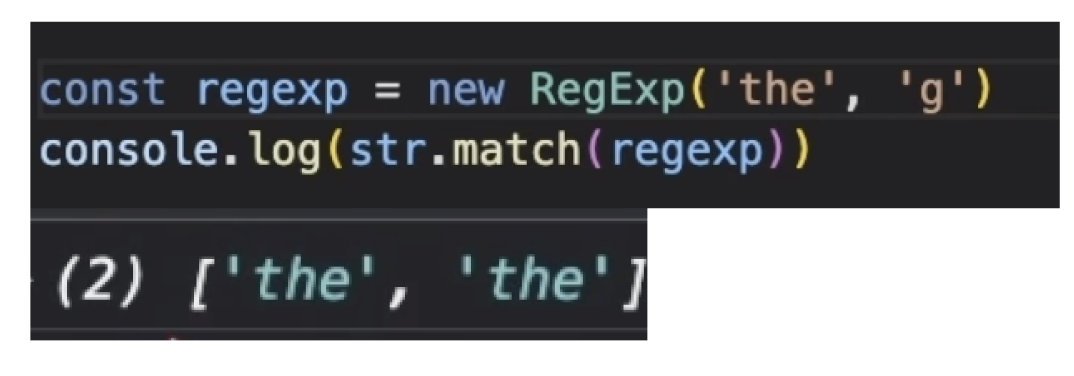
음 그런데 대문자가 포함된 The 는 찾지 못한다. 따라서 i 키워드를 붙여줘야한다. i 는 대소문자를 구분하지 않는다는 것을 의미한다.
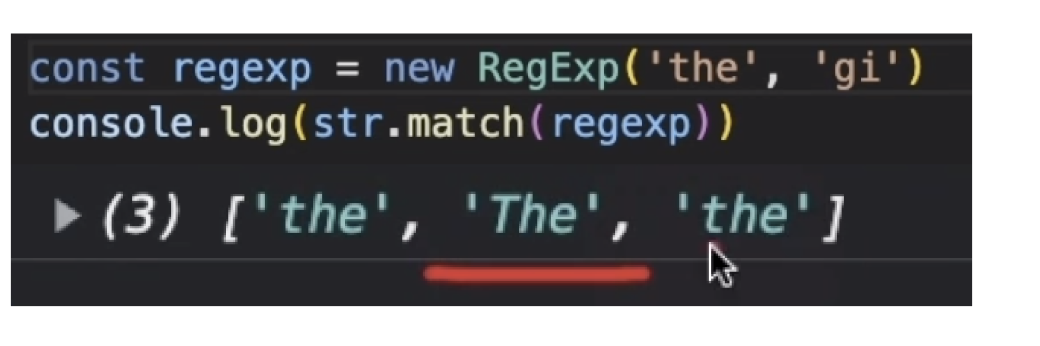
정규표현식은 생성자를 사용할 수도 있고, 리터럴 방식을 사용할 수도 있다.

메서드
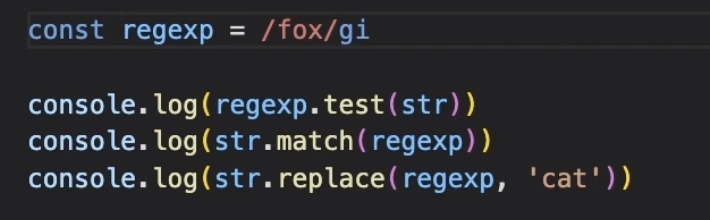
- 정규식.test(문자열) - 일치 여부 반환
- 문자열.match(정규식) - 일치하는 문자의 배열 반환
- 문자열.replace(정규식, 대체문자) - 일치하는 문자를 대체
플래그
- g - 모든 문자 일치(Global)
- i - 영어 대소문자를 구분 않고 일치(Ignore case)
- m - 여러 줄 일치(Multi line), 각각의 줄을 시작과 끝으로 인식
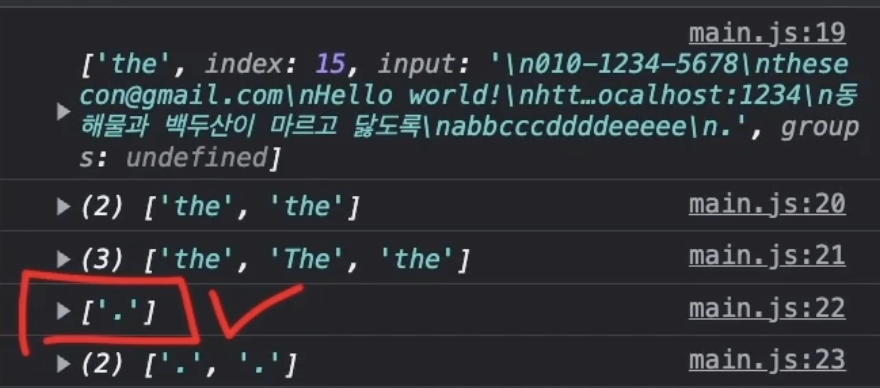
위 코드에서 \.$ 는 . 을 찾고싶은데 정규표현식에서 . 은 다른 의미가 있으므로 \. 으로 문자열 . 을 찾는다.
또한 $ 는 문자열 끝을 의미한다.
따라서 문자열의 끝에 . 을 찾는 것이다.
그러면 다음 정규표현식에서 다르게 된 것은 m 이라는 플래그 뿐인데 왜 다른 결과 값을 얻게 된 것일까?
console.log(str.match(/\.$/gim))
m 플래그가 없을 때
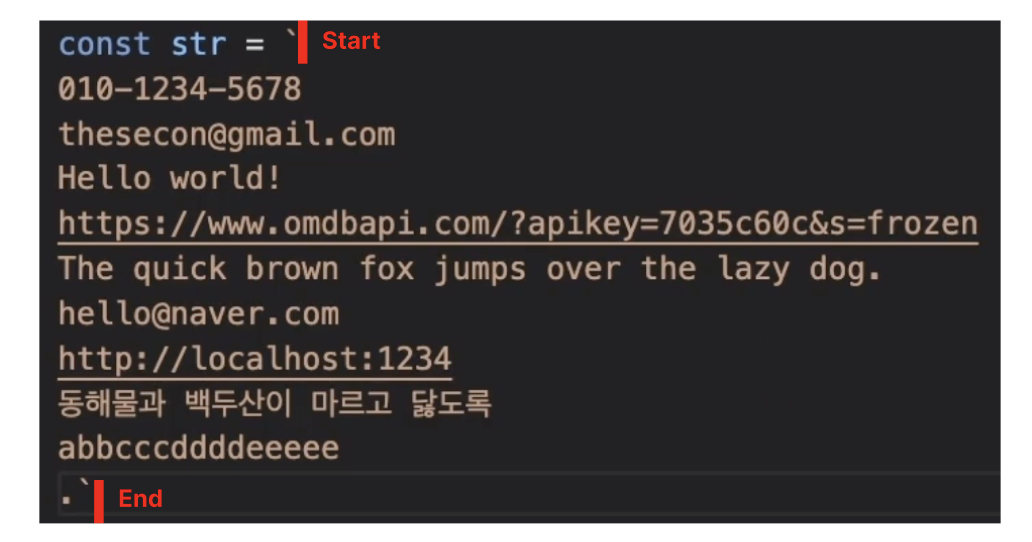
m 플래그가 있을 때
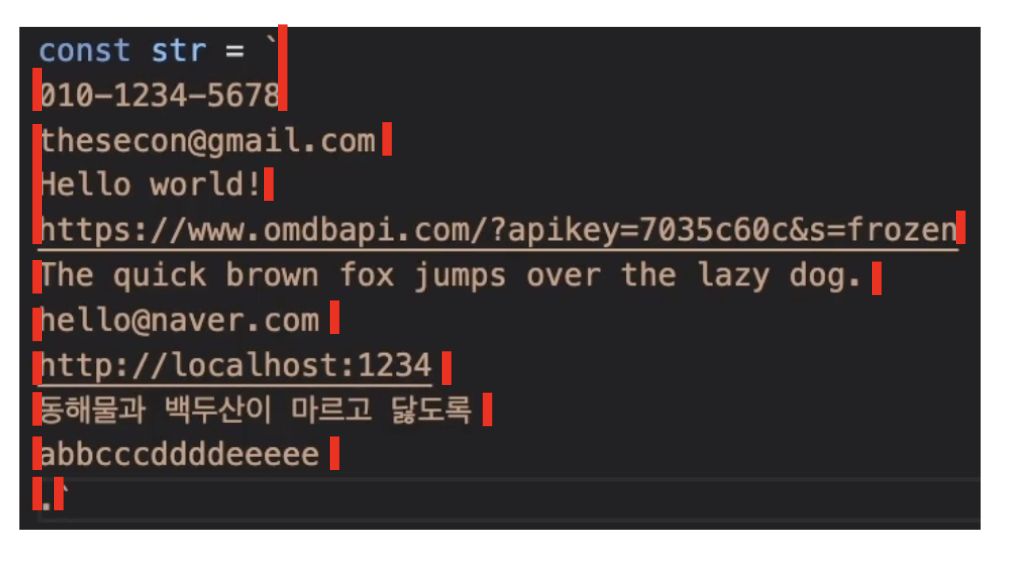
따라서 m 플래그를 사용했을 때 각각의 줄 마다 끝점이 생겨 . 이 두개 서치된 것이다.
패턴
const str = `
010-1234-5678
thesecon@gmail.com
Hello world!
https://www.omdbapi.com/?apikey=7035c60c&s=frozen
The quick brown fox jumps over the lazy dog.
hello@naver.com
http://localhost:1234
동해물과 백두산이 마르고 닳도록
abbcceddddeeeee
`;
// ^ab | 줄 시작에 있는 ab
console.log(str.match(/^h.../gm)); // ['http', 'hell', 'http']
// ab$ | 줄 끝에 있는 ab
console.log(str.match(/\.com$/gm)); // ['.com', '.com']
// . | 임의의 한 문자
console.log(str.match(/^h./gm)); // ['ht', 'he', 'ht']
// a|b | a 또는 b
console.log(str.match(/fox|dog/g)); // ['fox', 'dog']
// ab? | ab 또는 a
console.log(str.match(/https?/g)); // ['https', 'http']
// {3} | 3개 연속
console.log(str.match(/\d{3}/g)); // ['010', '123', '567', '703', '123']
// {3,} | 3개 이상 연속
console.log(str.match(/\d{3,}/g)); // ['010', '1234', '5678', '7035', '1234']
// {3,5} | 3개 이상 5개 이하 연속
console.log(str.match(/\d{3,5}/g)); // ['010', '1234', '5678', '7035', '1234']
// + | 1회 이상 연속 = {1,}
console.log(str.match(/\d+/g)); // ['010', '1234', '5678', '7035', '60', '1234']
// [abcd] | = a|b|c|d
console.log(str.match(/[foxdog]/g)); // ['o', 'g', 'o', 'o', 'o', 'd', 'o', 'd', 'o', 'f', 'o', 'o', 'f', 'o', 'x', 'o', 'd', 'o', 'g', 'o', 'o', 'o', 'o', 'd', 'd', 'd', 'd']
// [a-z] | a부터 z사이의 문자 구간
console.log(str.match(/[a-z]+/g)); // ['thesecon', 'gmail', 'com', 'ello', 'world', 'https', 'www', 'omdbapi', 'com', 'apikey', 'c', 'c', 's', 'frozen', 'he', 'quick', 'brown', 'fox', 'jumps', 'over', 'the', 'lazy', 'dog', 'hello', 'naver', 'com', 'http', 'localhost', 'abbcceddddeeeee']
// [A-Z] | A부터 Z사이의 문자 구간
console.log(str.match(/[A-Z]+/g)); // ['H', 'T']
console.log(str.match(/[a-zA-Z]+/g)); // ['thesecon', 'gmail', 'com', 'Hello', 'world', 'https', 'www', 'omdbapi', 'com', 'apikey', 'c', 'c', 's', 'frozen', 'The', 'quick', 'brown', 'fox', 'jumps', 'over', 'the', 'lazy', 'dog', 'hello', 'naver', 'com', 'http', 'localhost', 'abbcceddddeeeee']
// [0-9] | 0부터 9사이의 문자 구간 (숫자 판별)
console.log(str.match(/[0-9]+/g)); // ['010', '1234', '5678', '7035', '60', '1234']
// [가-힣] | 가부터 힣사이의 문자 구간 (한글 판별)
console.log(str.match(/[가-힣]+/g)); // ['동해물과', '백두산이', '마르고', '닳도록']
// \w | 63개 문자(대소영문 52개 + 숫자 10개 + _)
console.log(str.match(/\w+/g)); // ['010', '1234', '5678', 'thesecon', 'gmail', 'com', 'Hello', 'world', 'https', 'www', 'omdbapi', 'com', 'apikey', '7035c60c', 's', 'frozen', 'The', 'quick', 'brown', 'fox', 'jumps', 'over', 'the', 'lazy', 'dog', 'hello', 'naver', 'com', 'http', 'localhost', '1234', 'abbcceddddeeeee']
// \b | 63개 문자가 아닌 문자 경계
console.log(str.match(/\b[0-9]+\b/g)); // ['010', '1234', '5678', '1234']
// \d | 숫자
console.log(str.match(/\b\d+\b/g)); // ['010', '1234', '5678', '1234']
// \s | 공백 (스페이스, 탭, 줄바꿈)
console.log(str.match(/\s/g)); // ['\n', '\n', '\n', ' ', '\n', '\n', ' ', ' ', ' ', ' ', ' ', ' ', ' ', ' ', '\n', '\n', '\n', ' ', ' ', ' ', '\n', '\n']
// (?:) | 그룹 지정
console.log(str.match(/https?:\/\/(?:\w+\.?)+\/?/g)); // ['https://www.omdbapi.com/', 'http://localhost']
// (?=) | 앞쪽(Lookahead)
console.log(str.match(/.+(?=과)/g)); // ['동해물']
// (?<=) | 뒤쪽(Lookbehind)
console.log(str.match(/(?<=과).+/g)); // [' 백두산이 마르고 닳도록']
// 전화번호 추출
console.log(str.match(/\d{3}-\d{4}-\d{4}/g)); // ['010-1234-5678']
// 이메일 추출
console.log(str.match(/\w+@\w+\.\w+/g)); // ['thesecon@gmail.com', 'hello@naver.com']코드 출처: https://iam454.tistory.com/75
\b
시작과 끝도 경계에 포함된다는 것에 유의하자.

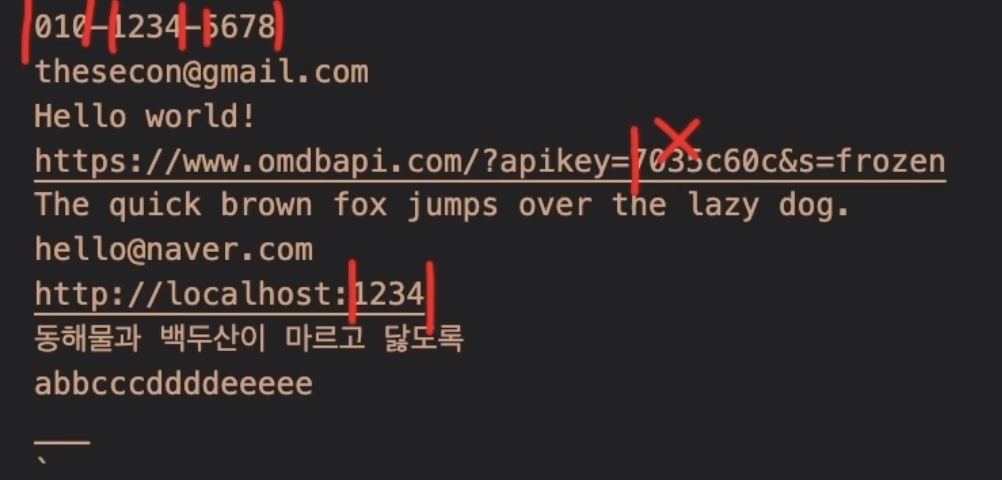

위의 7035c... 가 match 를 통과하지 못하는 이유는 경계가 | 7035c60c | & 인데 7035c60c 는 숫자로만 이루어진 값이 아니기 때문이다.
(?:) 그룹 지정
일정 패턴을 반복하게 해준다.

'카카오 테크 캠퍼스 > HTML CSS JS Advanced' 카테고리의 다른 글
| [카테캠 선택강의] JS 심화학습 (2) | 2023.05.27 |
|---|---|
| [카테캠 선택강의] 기타 Web APIs (1) | 2023.05.26 |
| [카테캠 선택강의] 반응형 적용 (0) | 2023.05.17 |
| [카테캠 선택강의] 섹션과 푸터 만들기 (2) | 2023.05.16 |
| [카테캠 선택강의] IntersectionObserver (2) | 2023.05.15 |